如何保证SDK的高可用
前言
SDK 作为第三方组件,对于客户来说是不太可控的。他们不清楚 SDK 内部的逻辑,也不可更改 SDK 的逻辑,一旦接入到自己的 APP 项目中,就相当于一个黑盒的存在。一旦这个 SDK 出现不可用情况,将会危及自己 APP 的正常运行,所以他们对于 SDK 的可用性是非常在意的。保证 SDK 的高可用也就成为 SDK 提供方的生命线
我这里用高可用而不用稳定性或者兼容性,因为我理解的高可用可以分为两块:
- SDK 的稳定性兼容性,也就是 SDK 的代码质量
- SDK 内部业务的高可用,不阻塞客户 APP 原本的正常流程
SDK 稳定性兼容性
这块光靠开发人员来保证肯定是不行的,任何一个开发都无法保证自己写的代码就一定没有问题。早期我们依赖于客户反馈,客户反馈一个崩溃我们就解决一个。这带来两个问题:
- 反馈的时间点不可控、提供的信息不可控,同时还存在很大的沟通成本。解决问题的及时性大打折扣,进而影响公司口碑
- 没有整体的质量数据,对于自己来说也是个黑盒
基于这两点我们决定开发崩溃采集基础 SDK,包含 java 层崩溃采集和 ndk 层崩溃采集
Java 层崩溃采集
Java 层崩溃采集原理比较简单,重置 Thread 的 DefaultUncaughtExceptionHandler
1 | |
整套采集的 UML 图
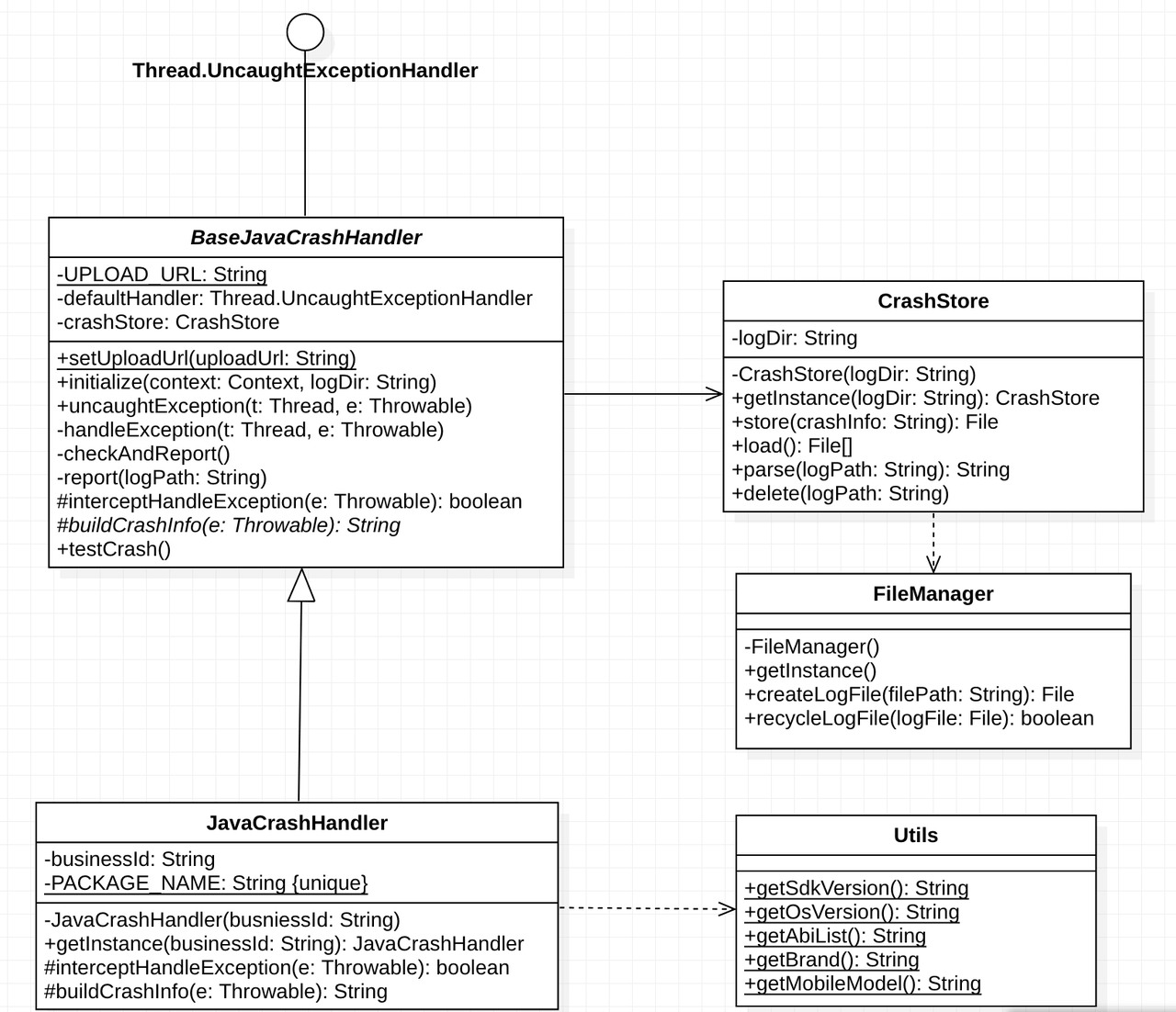
涉及的注意点
- 期望尽量立即上报
虽然方案中也提供了二次启动上报(依赖于堆栈文件存储)。我们知道崩溃会导致主线程退出,而上报是在子线程中进行的,这里就很大概率造成上报还没完成主线程已经退出了。这边利用 Thread.join(time) 尽量做到立即上报
1 | |
- 日志过滤
Thread 的 DefaultUncaughtExceptionHandler 会收集整个 APP 的崩溃,这对于我们有很大的干扰,同时也会增加上报平台的压力。理论上我们只关注 SDK 内部的崩溃,这里利用 packageName 过滤出我们想要的上报数据
1 | |
但是这也只能过滤一大部分,试想一下下面的场景:SDK 中定义了一个接口
1 | |
APP 中设置了这个接口,并且在回调方法中发生了崩溃
1 | |
这部分的崩溃数据目前的方案暂时无法过滤
整个方案依赖于 packageName,所以 packageName 一定不要混淆。在 proguard-rules.pro 中添加如下配置
1 | |
为了防止客户再次混淆,可以把混淆规则带在打出的 aar 包上。具体可以参考 混淆详解
- 崩溃日志向外抛出
SDK 崩溃采集的注册一般是后置的,整个崩溃链需要向外抛出,否则客户 APP 原本的 Java 层崩溃采集将失效
1 | |
日志还原
上报的数据部分是混淆后的代码,这部分代码不还原不太容易看懂。代码的还原依赖于 mapping.txt 文件,每次发布出去的 SDK 版本都需要保留 mapping.txt 文件,mapping.txt 和版本对应不上将很可能解不出来。具体可以参考 混淆详解
Ndk 层崩溃采集
在 Android 平台上,Ndk 层崩溃采集一直是比较麻烦的问题。因为捕获麻烦,获取到的内部又不全,内容全了信息又不对,信息对了又不好处理,比 Java 层崩溃采集不知道麻烦多少倍
与 Java 不同,c/c++ 没有一个通用的异常处理入口。在 c 层,CPU 通过异常中断的方式触发异常处理流程。不同的处理器,有不同的异常中断类型和中断处理方式,linux 把这些中断处理,统一为信号量,每一种异常都有一个对应的信号量
所有的信号量都定义在 <signal.h> 文件中,这里列一下我们需要关注的信号量
| 信号量 | 含义 |
|---|---|
| SIGABRT 6 | 调用 abort 函数生成的信号,表示程序异常 |
| SIGBUS 7 | 非法地址,包括内存地址对齐出错 |
| SIGFPE 8 | 计算错误,比如除0、溢出 |
| SIGILL 4 | 执行了非法指令 |
| SIGSEGV 11 | 非法内存操作,如向没有写权限的地址写数据 |
| SIGTRAP 5 | 断点时产生 |
| SIGSYS 31 | 非法的系统调用 |
| SIGSTKFLT 16 | 协处理器堆栈错误 |
- 可以注册回调函数处理需要关注的信号量
1 | |
核心是位于 <signal.h> 中的 sigaction 函数
1 | |
| 参数 | 含义 |
|---|---|
| __signal | 表示关注的信号量 |
| __new_action | 结构体指针;用于声明当某个特定信号发生的时候,应该如何处理 |
| __old_action | 结构体指针;他表示的是默认处理方式,当我们自定义了信号量处理的时候,用他存储之前默认的处理方式 |
循环给关注的信号量注册回调函数。这样每次发生崩溃的时候就会回调我们传入的 xc_crash_signal_handler 函数
- 获取错误信号和寄存器信息
来看下回调函数中三个参数的含义
| 参数 | 含义 |
|---|---|
| sig | 中断的信号量 |
| siginfo_t | 信号量信息的结构体指针 |
| uc | 是 uc_mcontext 的结构体指针,它封装了 cpu 的上下文 |
通过结构体指针 siginfo_t 可以获取信号量的以下信息
| 参数 | 含义 |
|---|---|
| si_signo | 中断信号量 |
| si_code | 中断信号 code |
| si_addr | 错误发生的地址 |
| si_pid | 发送信号的进程 id |
| si_uid | 发送信号的用户 id |
uc_mcontext 结构体指针中封装了 cpu 的上下文,包括当前线程的寄存器信息和崩溃时的 pc 值,能够知道崩溃时的 pc 值,就能知道崩溃时执行的那条指令。uc_mcontext 定义是平台相关的,比如我们熟知的 arm、arm64、x86。用宏定义大法就能获取当前 cpu 架构的寄存器信息
1 | |
1 | |
- 获取函数调用栈
获取堆栈信息比较麻烦,需要综合多种方案。常见的做法有四种:
- 直接使用系统的 <unwind.h> 库,可以直接获取错误文件和函数名。需要自己解析函数符号,同时经常会捕获到系统错误,需要手动过滤
- 在 4.1-4.4,使用系统自带的 libcorkscrew.so。5.0 开始,系统中没有了 libcorkscrew.so,可以自己编译系统源码中的 libunwind
- 使用开源库 coffeecatch,这种方法不能百分之百兼容所有机型
- 使用 Google 的 breakpad,这是所有 c/c++ 堆栈获取的权威方案。只不过这个库是全平台的,所以非常大,使用时需要把无关的平台剥离
- 当然还可以获取线程信息、内存信息等等,有用信息越多越有利于排查
涉及的注意点
- 以上获取到的 pc 值是程序加载到内存中的十进制绝对地址,绝对地址不能直接使用。需要通过 dladdr 函数获取偏移地址,偏移地址才能用 addr2line 分析出是哪一行代码
1 | |
- 日志上报放在应用层做
日志上报放在 java 层,上报的那部分代码可以复用。需要在 java 层添加一个 callback 的钩子,c++ 层日志文件记录完成调用这个钩子
1 | |
1 | |
日志过滤
注册信号量回调函数同样会上报整个 APP 的 Ndk 层崩溃,我们只关注 SDK 内部的 Ndk 层崩溃。因为我们上报的日志中同时会包含调用 Ndk 函数的 java 层入口堆栈,所以我们同样可以用 packageName 过滤的方式。为了防止 Ndk 内部崩溃没有 java 堆栈,我们添加关注的 so 名字作为辅助崩溃日志向外抛出
SDK 崩溃采集的注册一般是后置的,整个崩溃链需要向外抛出。我们给信号量注册回调函数的时候是存储了之前默认的处理方式的,在 xc_crash_signal_handler 中我们需要反注册将崩溃向外抛出
1 | |
- 信息尽量精简,不浪费服务器资源
日志还原
一个完整的 so 由 c 代码加一些 debug 信息组成。这些 debug 信息会记录 so 中所有方法的对照表,也就是符号表(可以类比于 java 的 mapping.txt)。这种 so 叫做未 strip的,通常体积会比较大。一般 release 的 so 都需要经过 strip,经过 strip 之后 so 中的 debug 信息会被剥离,体积会小很多。一般我们对外发布的 so 都是经过 strip 之后的
其实 gradle build 的过程中会生成 strip 前后的 so,不需要我们额外做什么操作
Cmake 中的是未 strip 的,stripped_native_libs 中的是经过 strip 的。mac 可以用 file 命令来检测 so 是否经过 strip,结尾是 not stripped 就是未经过 strip 的 so

带 debug 信息的 so 用于还原日志,所以每次发布版本都必须保留一份各个 cpu 架构带 debug 信息的 so。或者也可以直接把符号表剥离出来
下面来看一份完整的上报日志

初看难以理解,其实上报的日志还是有一定规律的
- 首先是一些环境信息,其中 ABI list 是必须的,也就是发生崩溃的手机的 cpu 架构。不同 cpu 架构的手机需要用不同架构的 so 还原
- Pid 是进程信息
- Signal 是错误信号,大概能知道是哪种类型的错误
- Backtrace 是堆栈信息,这部分是我们最应该关注的
从日志中只能看到偏移地址,比 java 混淆后的代码还难以理解。我们得从偏移地址中解出具体的代码位置。下面介绍两种工具
- addr2line 工具,位于 Ndk 目录下(位于 Android sdk 路径下)
1 | |
| 参数 | 说明 |
|---|---|
| NDK_VERSION | 编译 so 时候的 ndk 版本 |
| abi | 对应的 cpu 架构,上方日志表明是 arm64 |
| -C -f | 打印错误所在的函数 |
| -e | 打印错误地址的对应路径及行数 |
| debug.so | 对应 cpu 架构带符号表的 so |
| address | Backtrace 中的偏移地址,如 00009296 |
- Ndk-stack 工具,同样位于 Ndk 目录下
1 | |
| 参数 | 说明 |
|---|---|
| NDK_VERSION | 编译 so 时候的 ndk 版本 |
| abi | 对应 cpu 架构带符号表的 abi 文件夹,如 armeabi-v7a |
| dump.txt | 错误日志文件/一般把上报的日志拷贝到文件中 |
跨团队跨部门合作
Ndk 层崩溃定位另一个麻烦的点是可能涉及到跨团队跨部门合作,比如活体检测 SDK Ndk 层大部分的代码是算法团队写的。我们梳理了团队合作的问题分配或者说合作模式
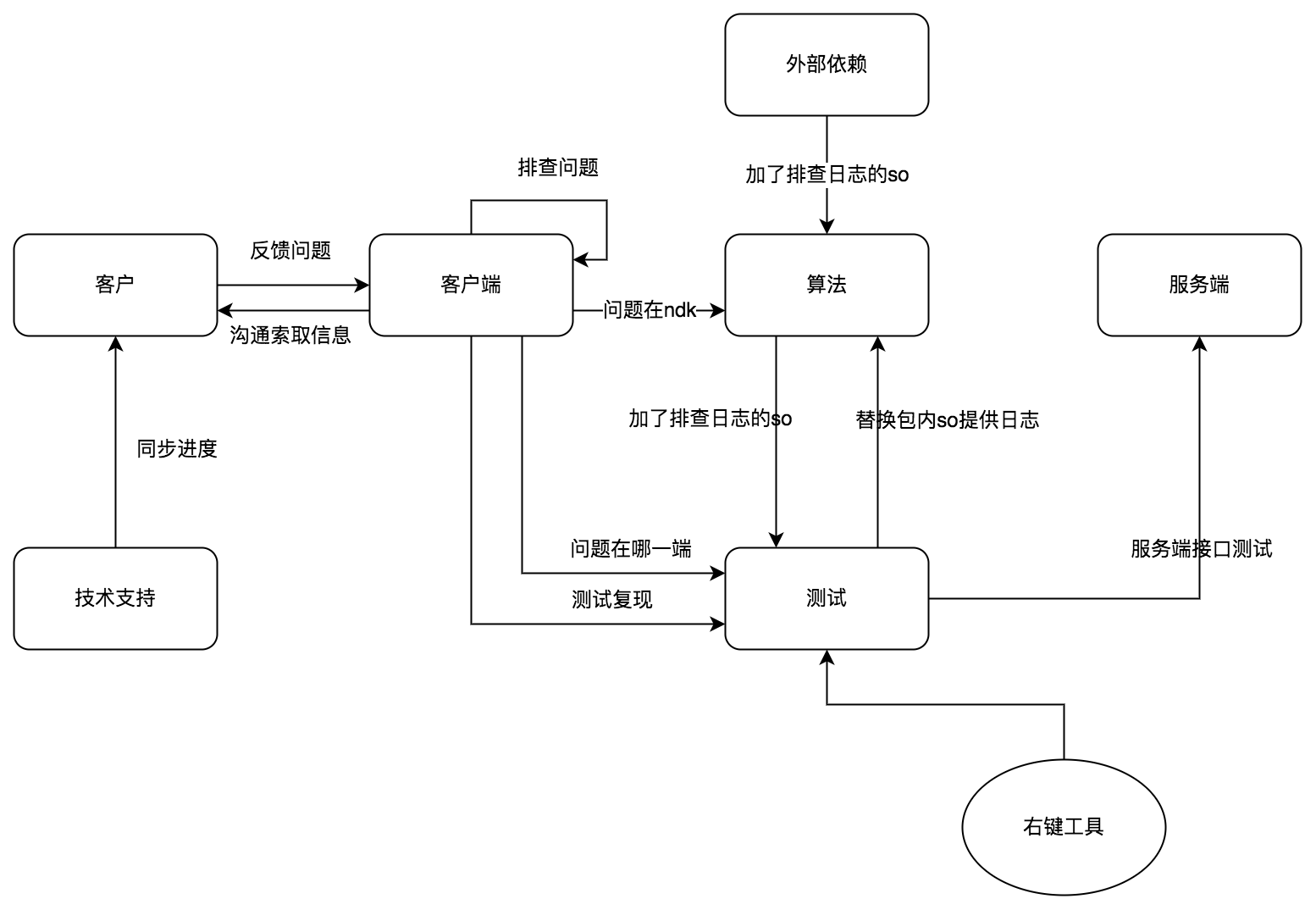
经验:
- 最好在客户 APP 中测试,很多问题在 demo 中并不好复现
- 把技术赋能给其他团队同事,把自己释放出来干其他更重要的事。当然移动端提供协助是不可避免的,这是移动端的属性决定的
可视化平台
数据采集完之后就要搭建可视化平台了,说白了就是要搭建类似于 bugly 一样的平台便于开发人员操作
内部业务高可用
在我看来单纯的保证 SDK 的稳定性兼容性是远远不够的,还得保证尽量不影响客户 APP 原本的正常流程。细想一下有些 SDK 其实是很前置的,比如我们的活体检测 SDK,用户只有在活体检测流程通过之后才能走后面的流程。而 SDK 运行的环境是不可控的,任何一个节点的异常都有可能导致用户无法向下进行。所以要保证 SDK 内部业务的高可用其实是更加困难的
为了保证业务的高可用我们进行了如下工作:
打印各流程节点耗时
Debug 环境打印各流程节点耗时,以此为依据尽量缩短各流程节点的耗时
多域名重试机制
针对海外布局的产品可能服务器的稳定性比较差,我们加了多域名重试机制尽可能的提高接口的稳定性
全链路埋点
梳理 SDK 内部业务的所有流程节点,拿活体检测 SDK 为例
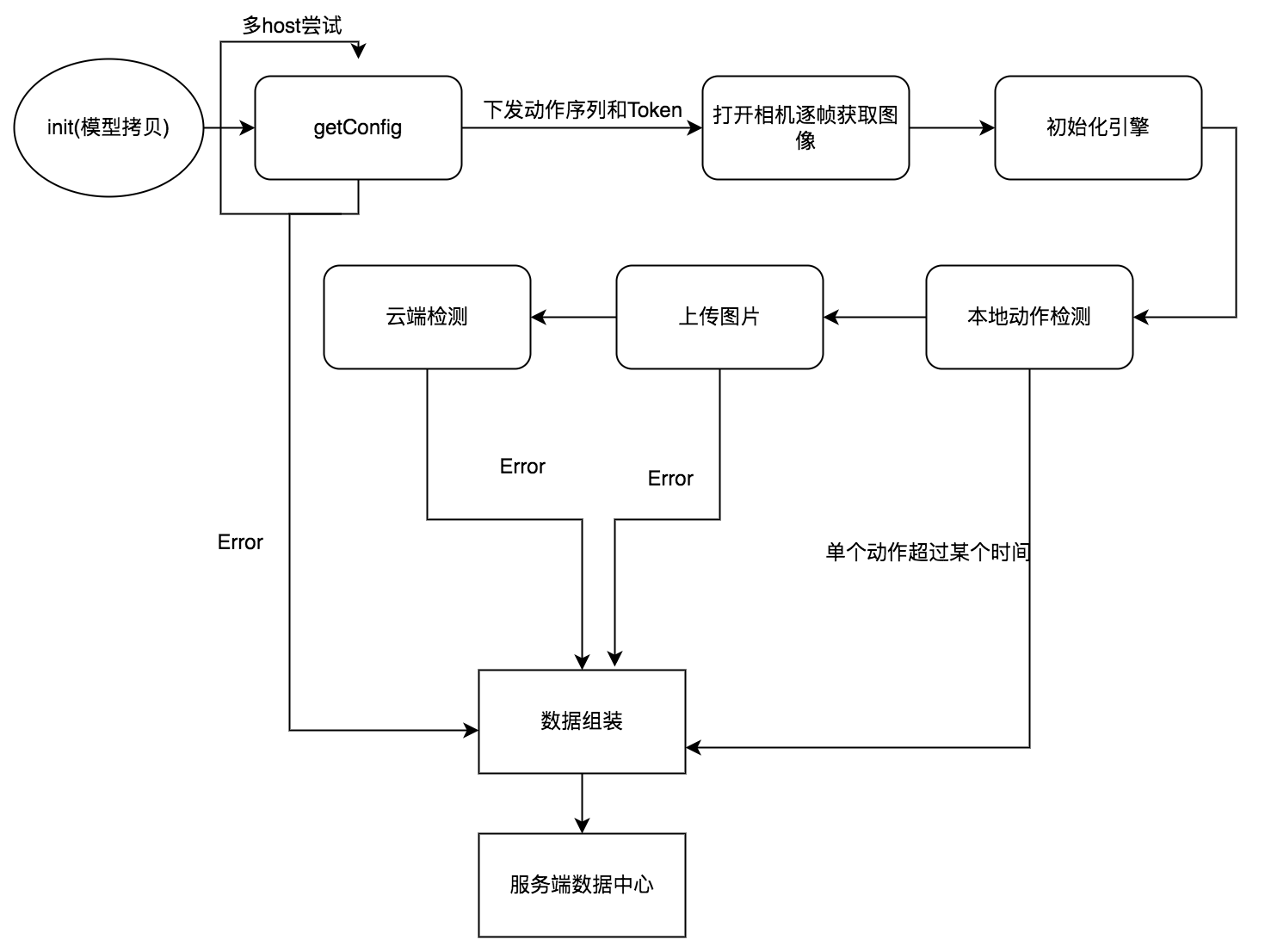
在各个节点加数据埋点,这个过程一定要细致。通过上报的数据来分析哪些节点比较容易出问题
降级处理
针对于比较容易出问题的节点客户端做降级处理,服务端来保证整个流程的安全性。比如本地动作检测不容易通过就降级本地检测动作的数量或者阈值
其他建议
- 回调中千万不要包含空指针参数,客户使用不可控
- 在不阻碍业务流程的基础上合理加 try catch
- 错误原信息正确清晰得返回给客户,最好容易理解
- Demo 也需要好好打磨,客户会或多或少参考 demo 中的代码
总结
要持续保持 SDK 的高可用还有很长的路要有,上面的一些方案也还有不少优化空间,共勉
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!